
URL Scanner HTML Parser
URL Scanner application video Demo
Objective
Develop a web application which scans the provided Hostname/URL to gather following information:
- IP Address of provided Hostname/URL.
- Redirection URL (If given Hostname/URL is redirecting to some other location).
- Website Title.
- Text content present inside <body> tag of the website DOM.
Note: Web site Title and Body Content should contain valid English letters or words only, everything else should be filtered out like encoded html quotes and characters.
- No. of Images present in the website DOM.
- No .of links present in the website DOM. (<a>)
Technology Used:
- Spring Boot with Hibernate JPA support
- Static html pages hosted in spring boot with AJAX implementation for dynamic data
- Mysql database to store the records
- Rest services for data fetch, update and add.
- Git repository to store our code
Steps:
- Install java8
- Install gradle
- Add STS support plugins for eclipse
- Install Mysql database and mysql workbench
- get spring boot project readymade template from https://start.spring.io/
Install Mysql database and mysql workbench
- sudo apt-get update
- sudo apt-get install mysql-server
Provide password for root user while install going on.
Create user,
create database <db_name>;
create user <user_name>@'localhost' identified by '<password>';
grant all on db_name.* to '<user_name>';
create user <user_name>@'localhost' identified by '<password>';
grant all on db_name.* to '<user_name>';
To access from Terminal:
$mysql -u <user_name> -p enter and provide password

To access DB from mySql workbench:
Install mysql workbench with $sudo apt-get install mysql-workbench
Add db username and password as shown below:

Create Table Query:
To Store data, we will create below database table :
CREATE TABLE `url_scan_details` (
`url_id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`url` varchar(255) NOT NULL DEFAULT '',
`redirect_url` varchar(255) DEFAULT NULL,
`status` tinyint(1) NOT NULL DEFAULT '0',
`ip_address` varchar(15) DEFAULT NULL,
`website_title` varchar(100) DEFAULT NULL,
`website_body` longtext DEFAULT NULL,
`image_count` int(11) DEFAULT NULL,
`link_count` int(11) DEFAULT NULL,
`submitted_on` datetime DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`url_id`),
UNIQUE KEY `url` (`url`)
)
That is all about from database setup side. Next We will see spring boot and database access from Spring Hibernate JPA.
To get springboot project readymade:
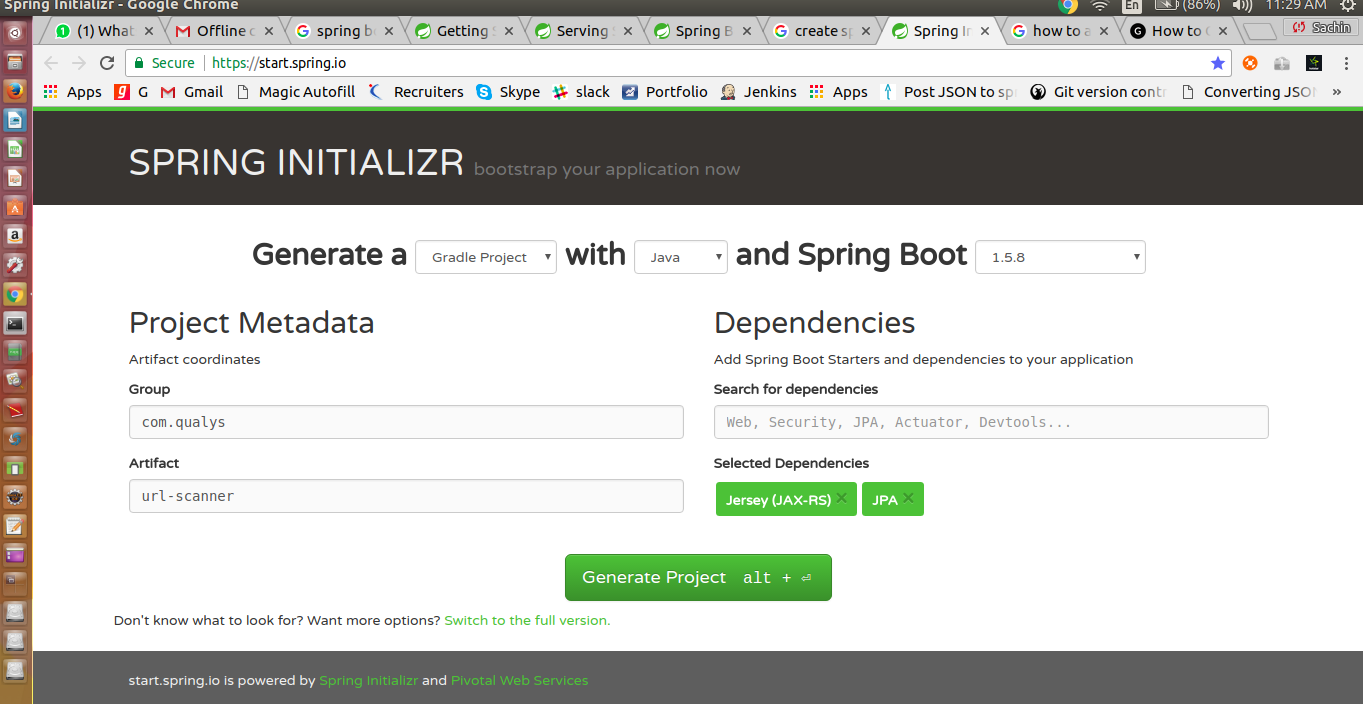
extract downloaded zip file and import this project to eclipse as gradle project as shown below:
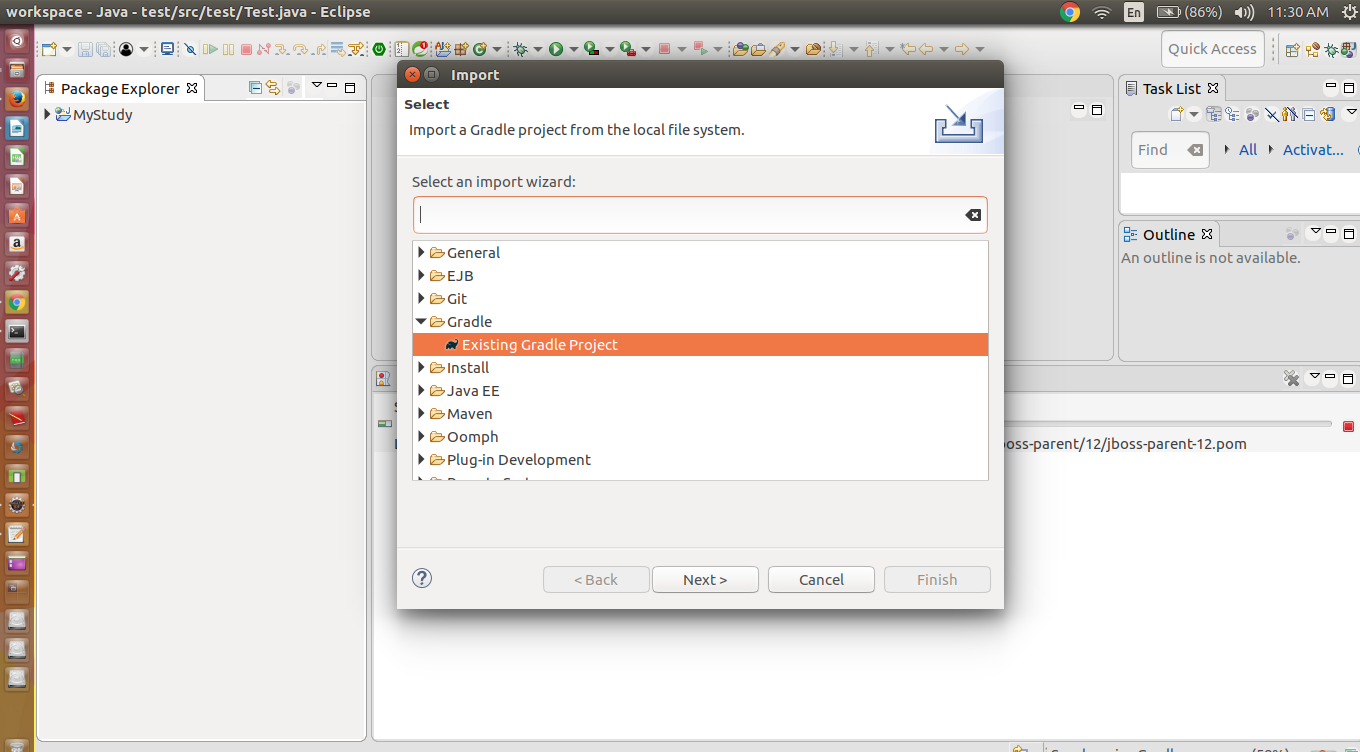
Use, $./gradlew bootRun to run the spring boot project.
Git Repository
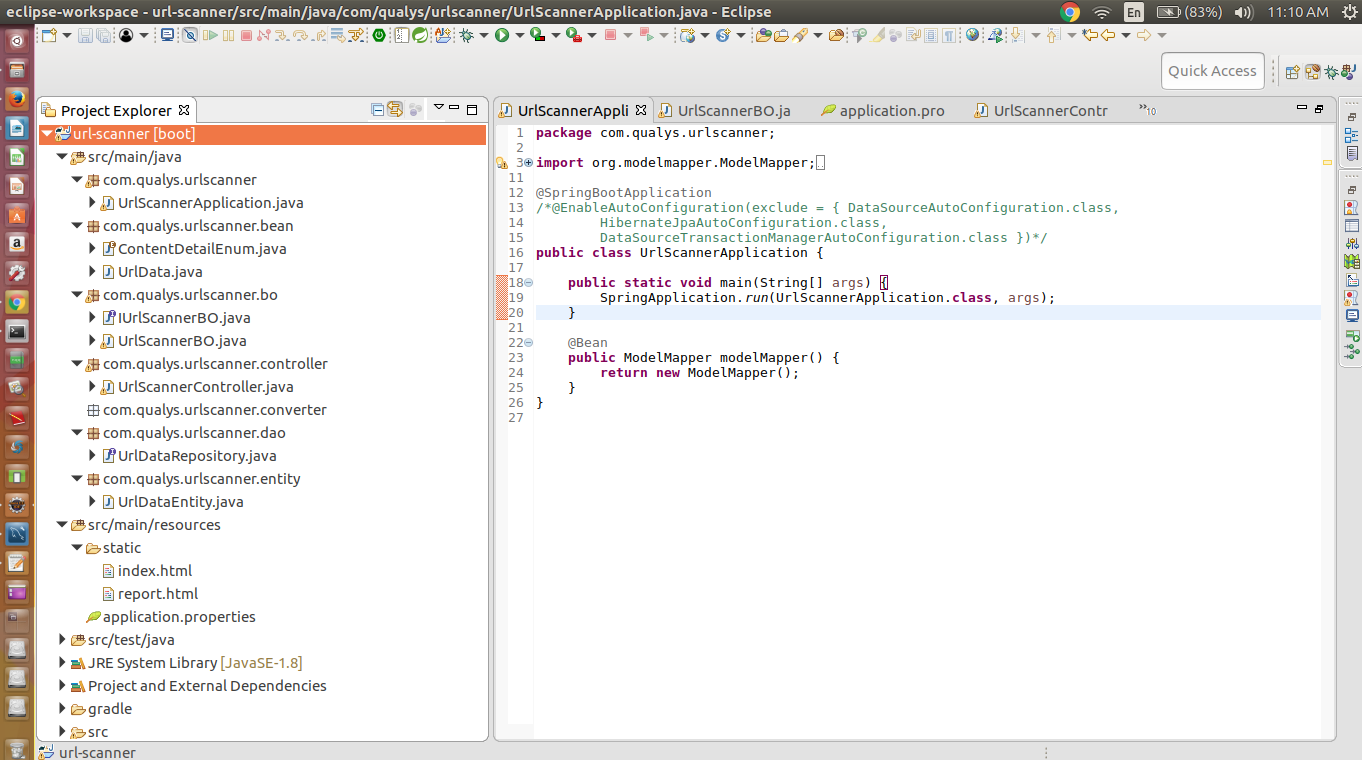
Project Directory Structure With code added:
Below image shows java controller, Bo, Dao classes, static html files and application.properties files required for the project:
Class Diagram:

Functional Specification:
When we start application we will get default home screen with last url scanned 10 records.
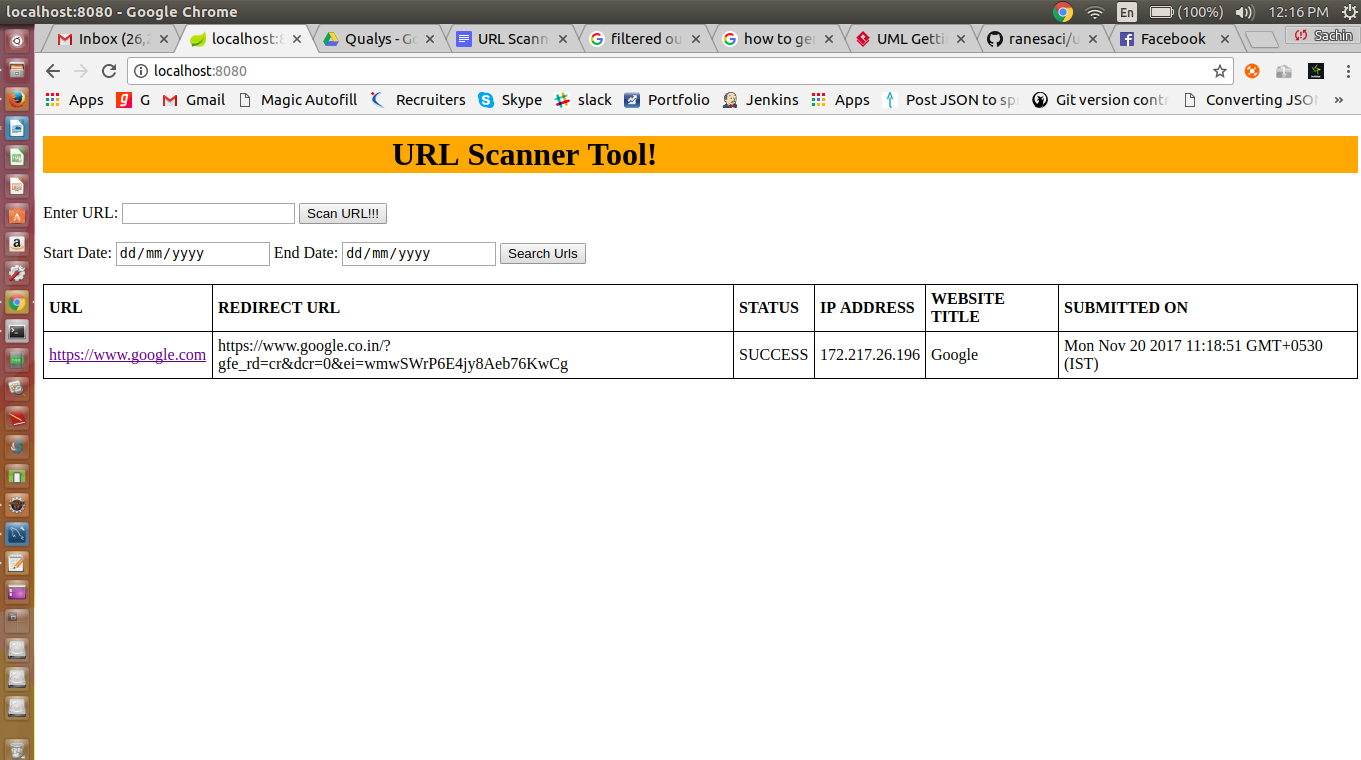
Add url for scan
To scan Url, enter url with http or https protocol andd click on Scan Url button.
For Example, I am using this Url : https://youtu.be/5cUj9-az3Z8

When clicked on Scan button, we are getting alert than Scan successful or not and you can see the scanned record in the table.
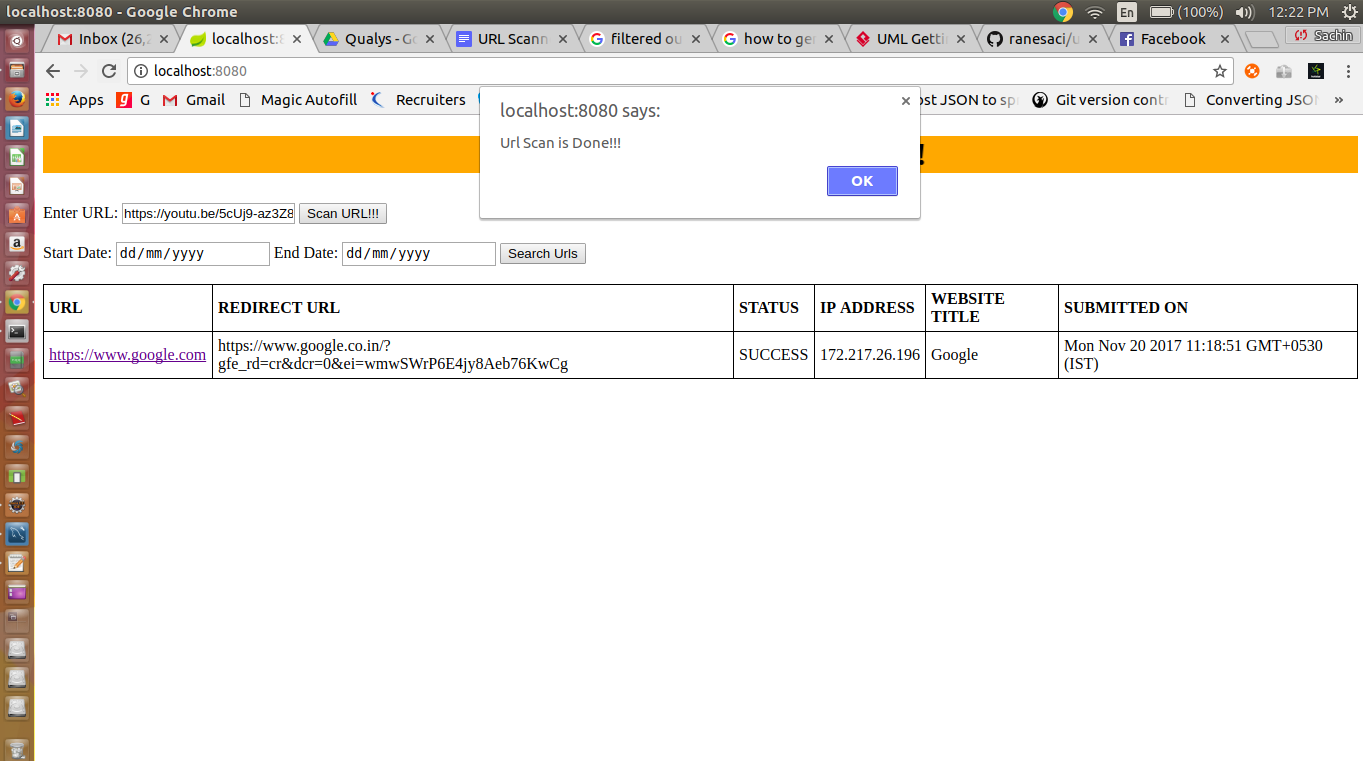
When we click on Alert OK button, we will see below:
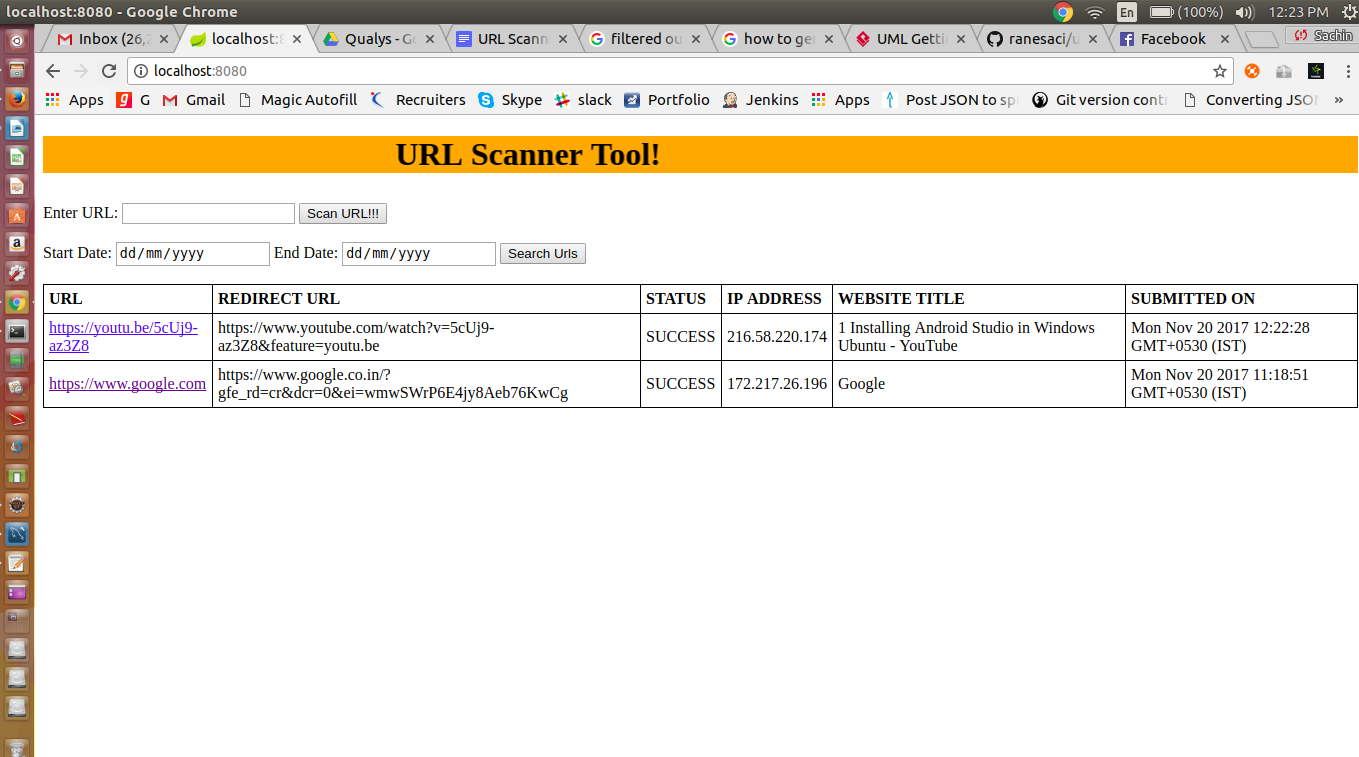
Scan Url details report
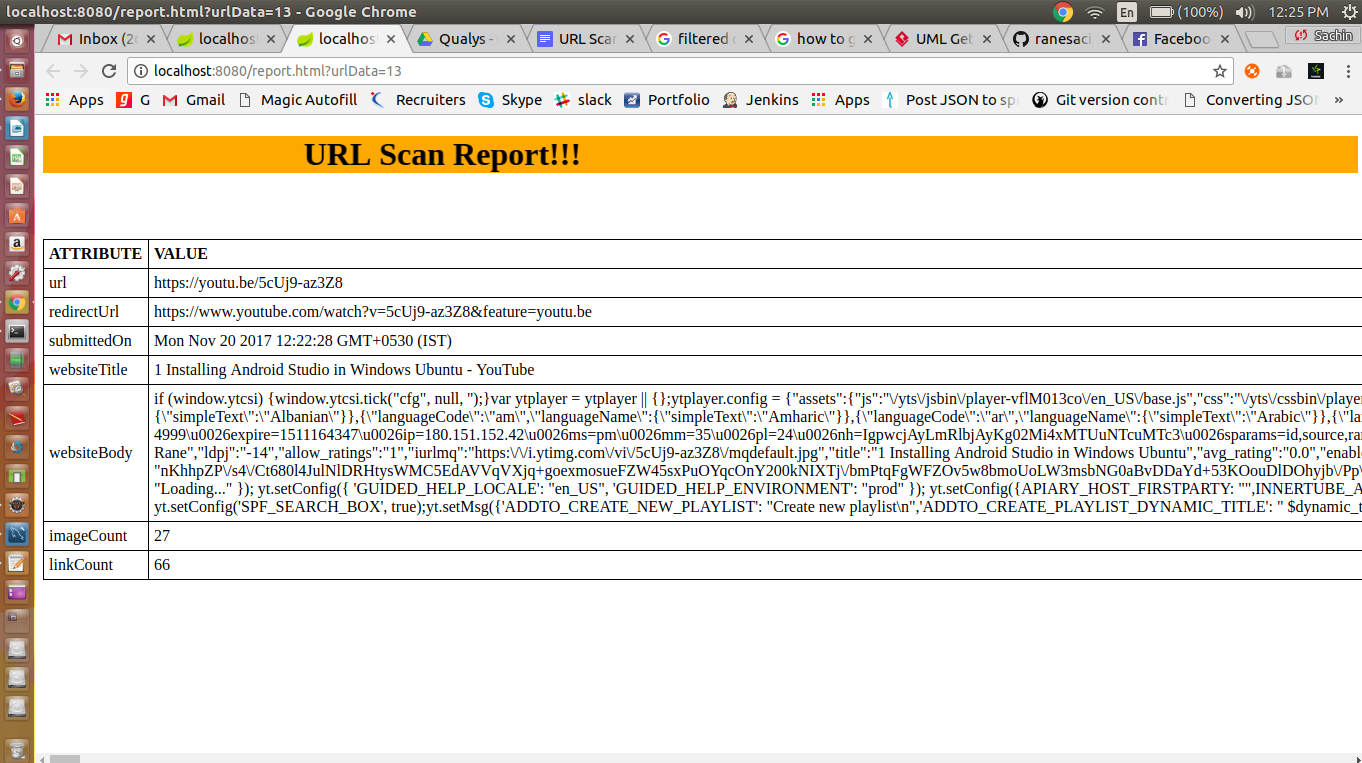
To get the url details scan report, click on the hyperlink, it will go to new page as shown below.
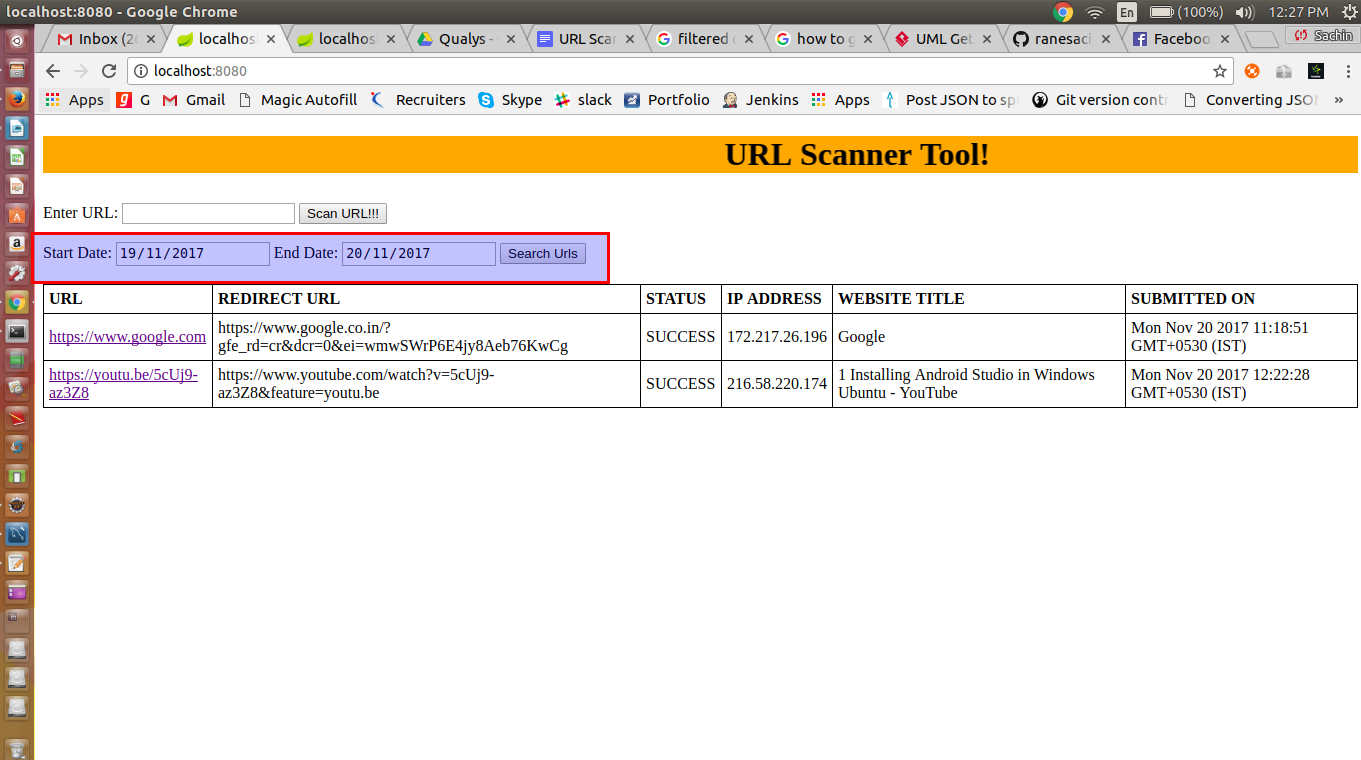
To find Url scanned records between 2 given date:
Provide start date and end date to fetch the records in the table as shown below:
Validations:
- When Url to be scanned in empty or not starting with with http
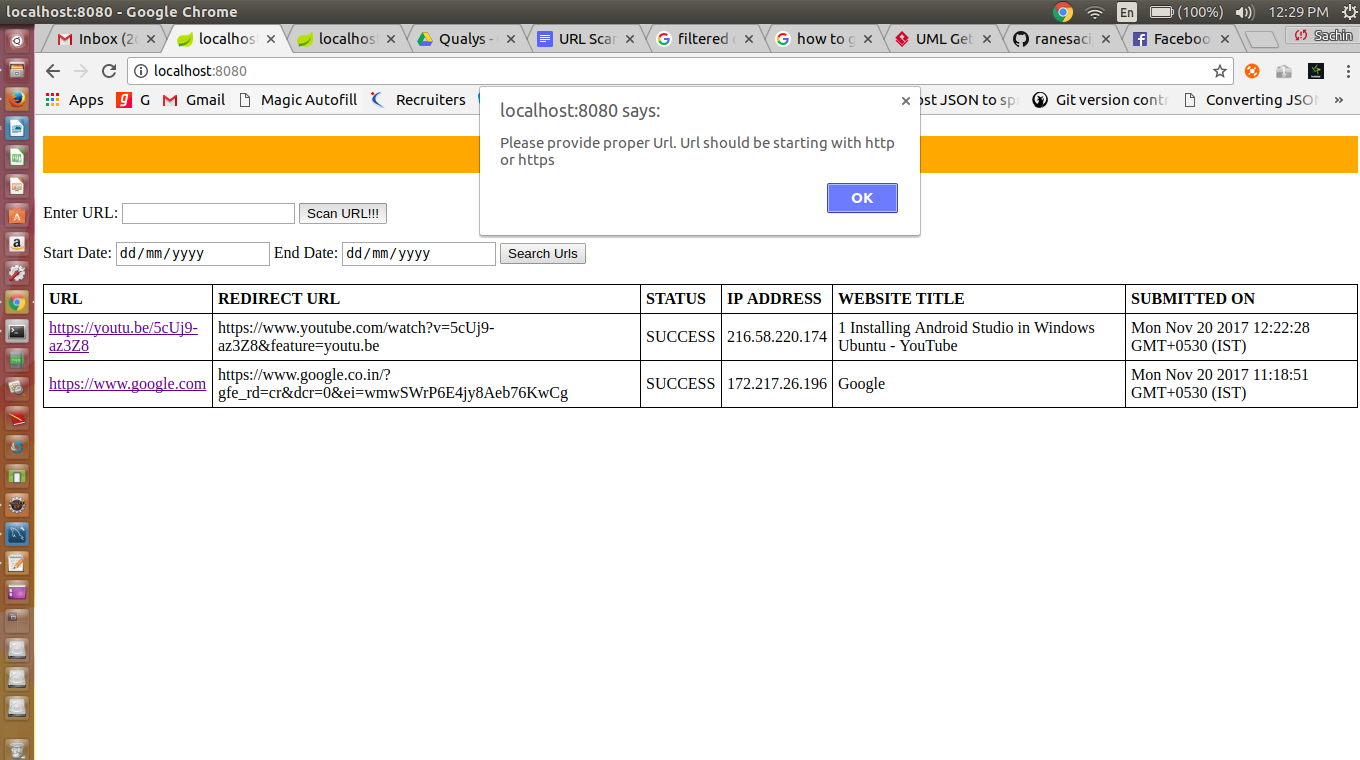
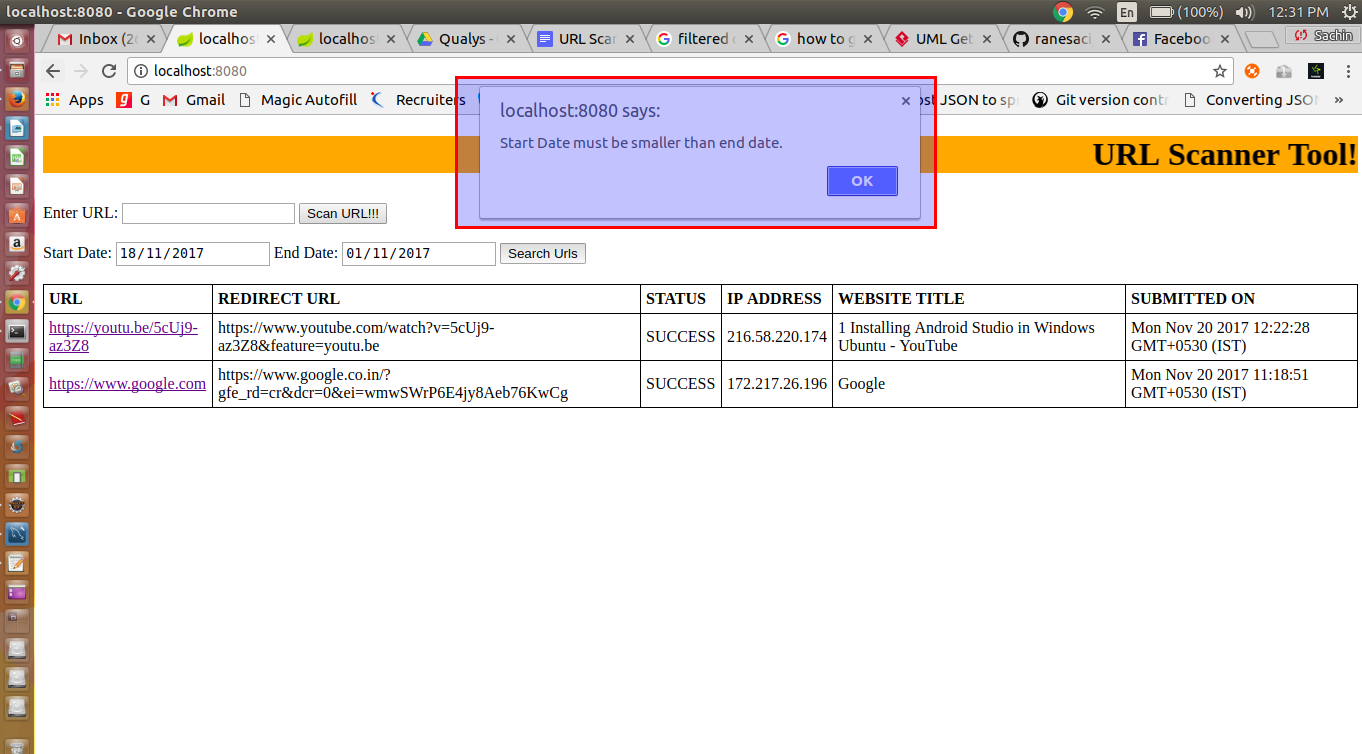
2. When only one date provided or end date smaller than start date
We can use RabbitMq or any Queue mechanism to scale this application to support multiple concurrent request.
1. Functional and Technical specification document.
URL: https://docs.google.com/
2. Video Demo for application
3. Git Repository for the project

No comments:
Post a Comment