Hi,
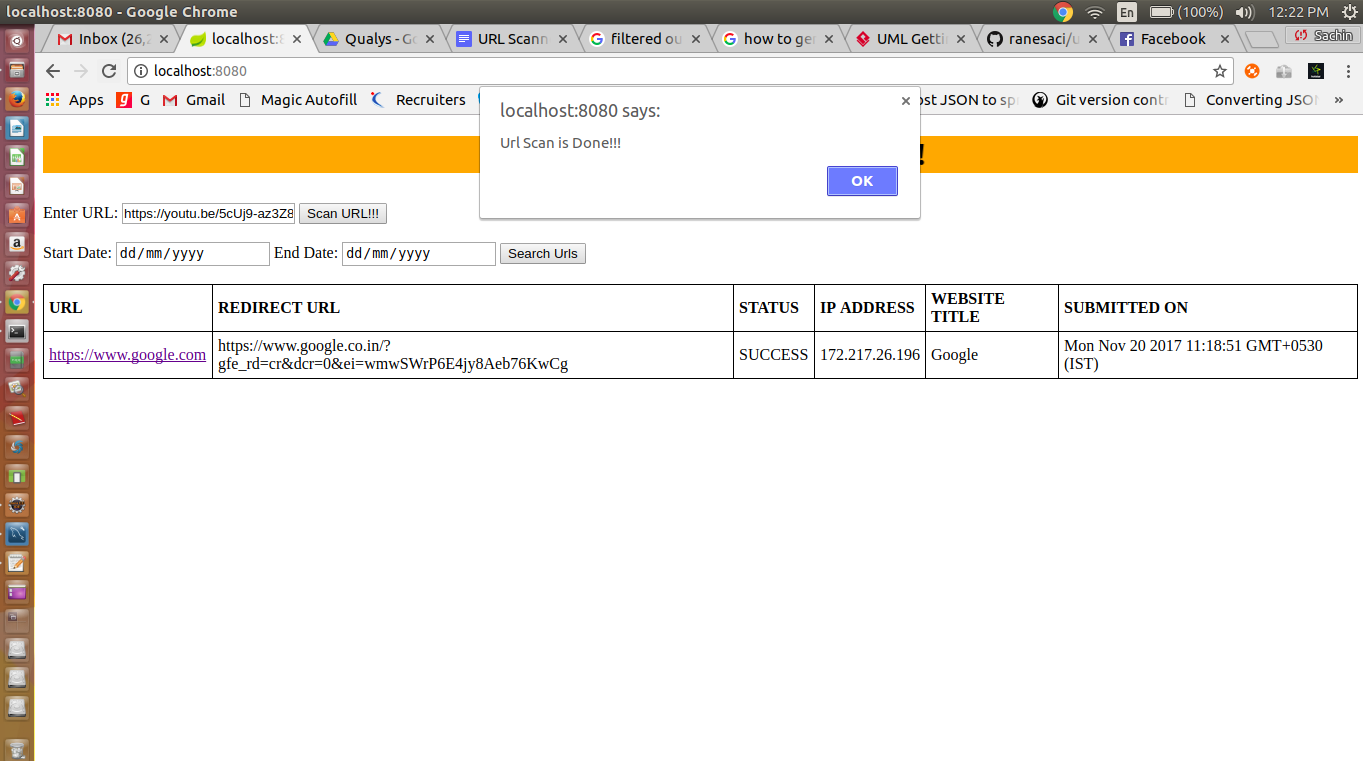
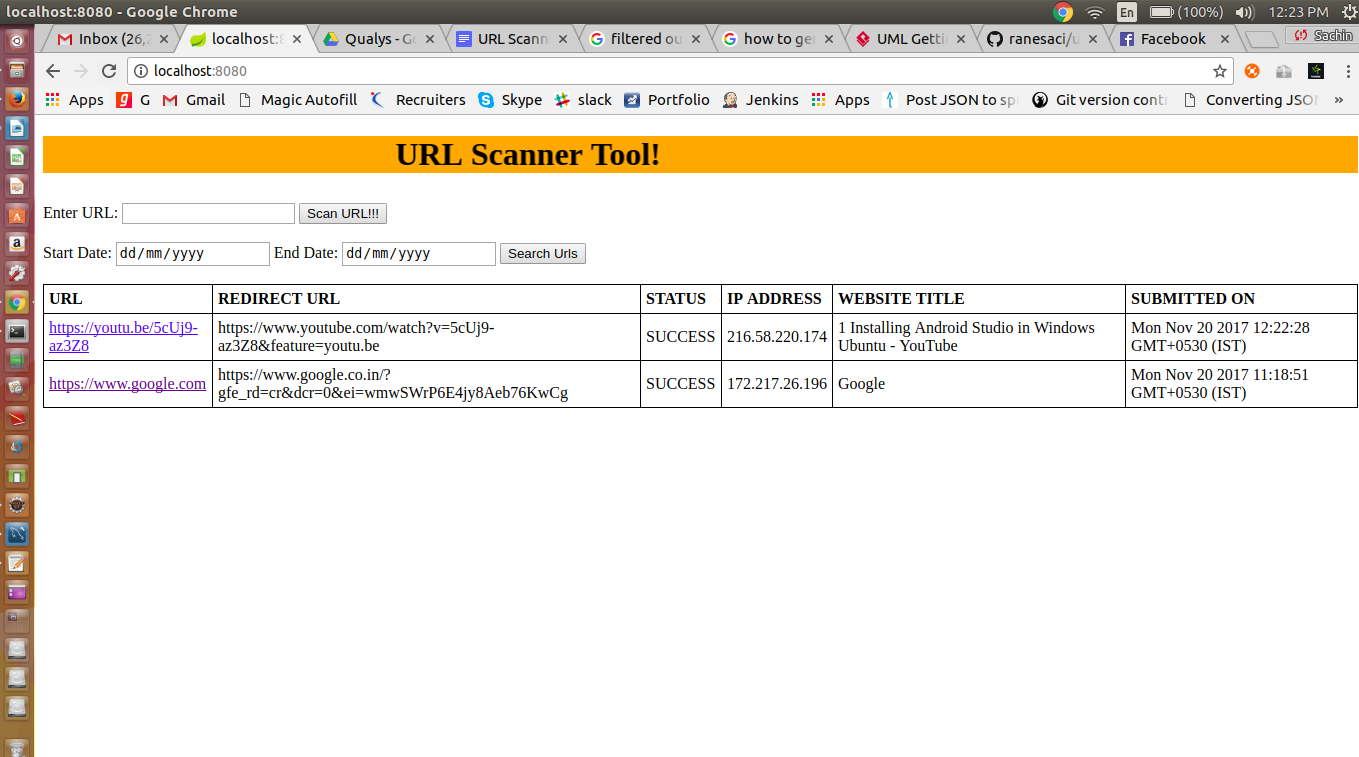
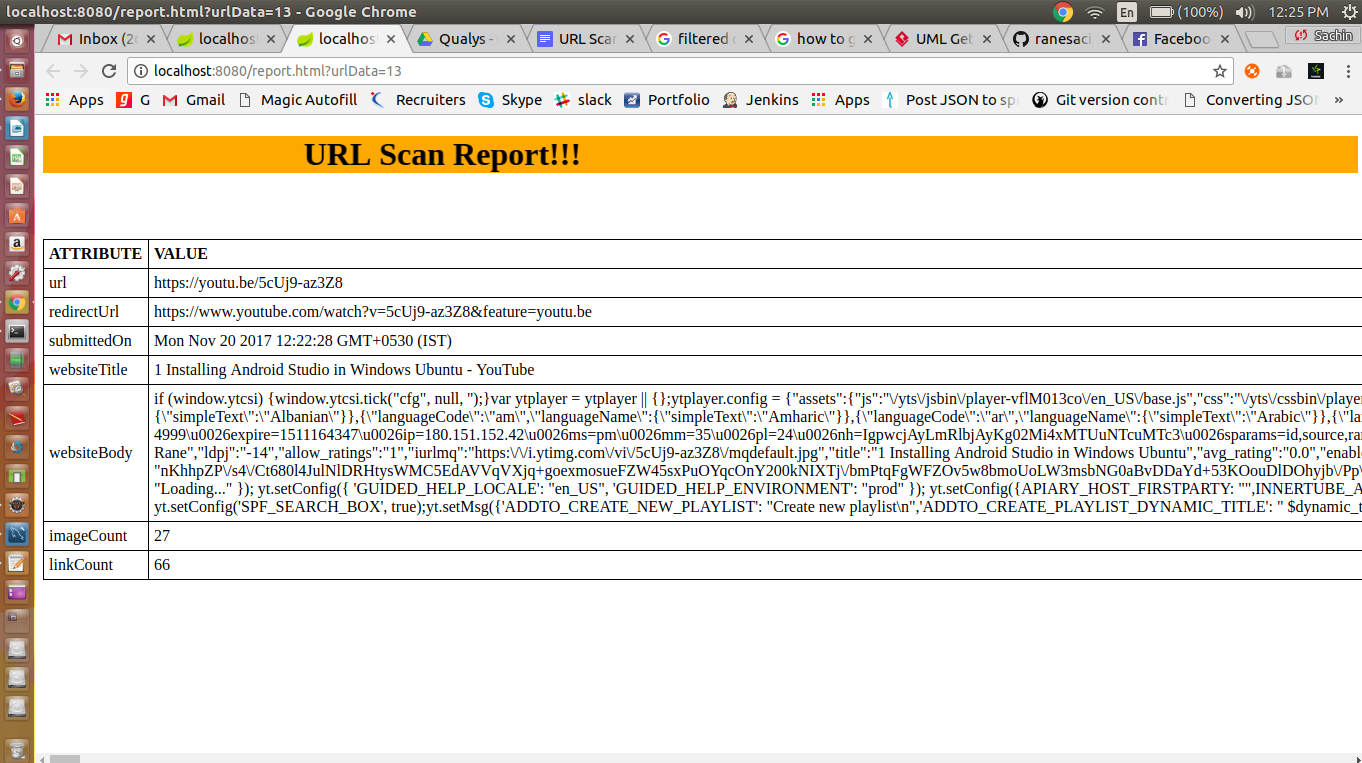
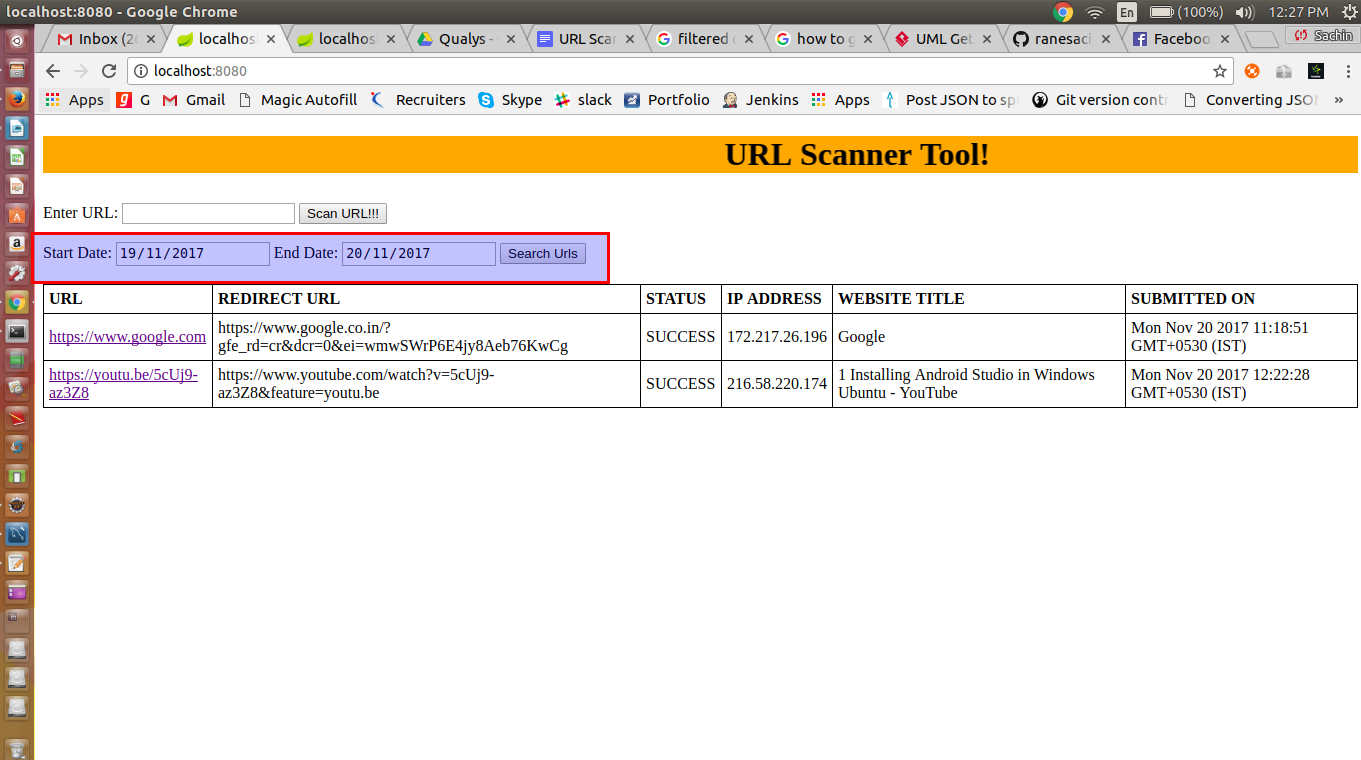
To read the jar file data, we can use JarFile and JarEntry classes and read files. Below is the video demo and code for the same.
To read the jar file data, we can use JarFile and JarEntry classes and read files. Below is the video demo and code for the same.
Video Demo
Code:
package other;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.jar.JarEntry;
import java.util.jar.JarFile;
public class ReadJarFilesContents {
public static void main(String[] args) {
String JAR_PATH = "/home/sachin/created jar/url-scanner-0.0.1-SNAPSHOT.jar";
readJarContents(JAR_PATH);
}
public static void readJarContents(String jarFileToRead) {
JarFile jarFile = null;
try {
jarFile = new JarFile(jarFileToRead);
JarEntry entry = jarFile.getJarEntry("BOOT-INF/classes/application.properties");
InputStream inputStream = jarFile.getInputStream(entry);
InputStreamReader inputStreamReader = new InputStreamReader(inputStream);
BufferedReader bufferedReader= new BufferedReader(inputStreamReader);
String read = null;
StringBuffer sb = new StringBuffer();
while((read = bufferedReader.readLine()) != null) {
sb.append(read+ "\n");
}
System.out.println(sb.toString());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
OutPut:
spring.datasource.url= jdbc:mysql://localhost:3306/test1
spring.datasource.username=sachin
spring.datasource.password=Sachin@123
#spring.jpa.hibernate.ddl-auto=create-drop
# Number of ms to wait before throwing an exception if no connection is available.
spring.datasource.tomcat.max-wait=10000
# Maximum number of active connections that can be allocated from this pool at the same time.
spring.datasource.tomcat.max-active=150
# Validate the connection before borrowing it from the pool.
spring.datasource.tomcat.test-on-borrow=true
# Hibernate ddl auto (create, create-drop, update): with "update" the database
# schema will be automatically updated accordingly to java entities found in
# the project
spring.jpa.hibernate.ddl-auto = update
# Naming strategy
spring.jpa.hibernate.naming-strategy = org.hibernate.cfg.ImprovedNamingStrategy
# Allows Hibernate to generate SQL optimized for a particular DBMS
spring.jpa.properties.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
#logging
logging.level.org.springframework.web=ERROR
com.qualys.urlscanner=DEBUG
logging.file=/home/sachin/log/url-scanner.log